
SQL 简明手册 入门篇
简介
数据库(DBMS)分为关系型数据库(RDBMS)和非关系型数据库(NoSQL),SQL 全称 Structured Query Language 即结构化查询语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL标准命令
与关系数据库交互的标准SQL命令是创建、选择、插入、更新、删除和删除,简单分为以下几组:
- DDL(数据定义语言)
数据定义语言用于改变数据库结构,包括创建、更改和删除数据库对象。 - DML(数据操纵语言)
数据操纵语言用于检索、插入和修改数据,数据操纵语言是最常见的SQL命令。 - DCL(数据控制语言)
数据控制语言为用户提供权限控制命令。
SQL 数据检索
基本检索 SELECT
SELECT * FROM <表名>; -- 查询所有字段
SELECT <字段1>, <字段2>, ... FROM <表名>; -- 查询指定字段
SELECT DISTINCT <字段1>, <字段2>, ... FROM <表名>; -- 列出不重复的查询结果
SELECT 1+2; -- 使用SELECT进行运算
许多检测工具会执行一条 SELECT 1; 来测试数据库连接。
FORM后可接多个表名:
SELECT * FROM <表1>, <表2>;
这种查询会返回二维表,其中行数是多个表的乘积,列数是多个表列数的和,查询结果包含所有表所有记录的排列组合,称为表的内连接。
条件检索 WHERE
SELECT <字段名> FROM <表名> WHERE <条件>; -- 查询指定条件下指定字段
WHERE 子句不仅用于 SELECT 语法,还用于 UPDATE,DELETE 语法等。
可以使用 AND OR NOT 链接条件表达式。
注意:
文本字段使用单引号 '' (部分数据库也接受双引号),数值字段不使用引号。
检索结果排序 ORDER BY
SELECT <字段1>, <字段2>, ... FROM <表名> ORDER BY <字段1>;
-- 按某一字段名排序查询结果,默认生序排序
SELECT <字段1>, <字段2>, ... FROM <表名> ORDER BY <字段1> ASC; -- 升序排序
SELECT <字段1>, <字段2>, ... FROM <表名> ORDER BY <字段1> DESC; -- 降序排序
SELECT <字段1>, <字段2>, ... FROM <表名> ORDER BY <字段1> ASC,<字段2> DESC, ... ;
-- 多重规则的排序,写在前面的字段规则更优先
检索结果截取 LIMIT
LIMIT子句用于指定要返回的记录数量。
SELECT <字段名> FROM <表名> LIMIT <M>;
-- 截取查询结果的前M行记录
SELECT <字段名> FROM <表名> LIMIT <M> OFFSET <N>;
-- 截取查询结果从第N行开始的M行记录
注意,此处以MySQL为例,某些数据库系统写法不同,比如 SQL Server 使用的是TOP语法。
检索结果连接 JOIN
JOIN链接
连接(JOIN)子句用于将数据库中两个或者两个以上表中的记录组合起来。连接通过共有值将不同表中的字段组合在一起。
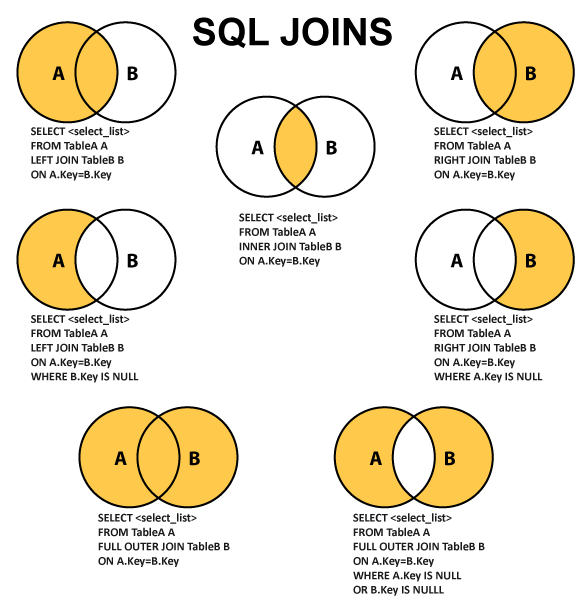
SELECT ... FROM <表1> INNER JOIN <表2> ON <条件>;
-- INNER JOIN 可以简写为 JOIN
SELECT ... FROM <表1> LEFT OUTER JOIN <表2> ON <条件>;
-- LEFT OUTER JOIN 可以简写为 LEFT JOIN
SELECT ... FROM <表1> RIGHT OUTER JOIN <表2> ON <条件>;
-- RIGHT OUTER JOIN 可以简写为 RIGHT JOIN
SELECT ... FROM <表1> FULL OUTER JOIN <表2> ON <条件>;
-- FULL OUTER JOIN 可以简写为 FULL JOIN
INNER JOIN是选出两张表都存在的记录;LEFT OUTER JOIN是选出左表存在的记录,仅右表存在的记录填充NULL;RIGHT OUTER JOIN是选出右表存在的记录,仅左表存在的记录填充NULL;FULL OUTER JOIN则是选出左右表都存在的记录,仅左表或右表存在的记录填充NULL。
自连接
实际上使用了内连接的方法,把自身看做两张表。
SELECT <字段1>, <字段2>, ...
FROM <表> T1, <表> T2
WHERE <条件>;
检索结果组合 UNION
UNION 子句/运算符用于将两个或者更多的 SELECT 语句的运算结果组合起来。
- UNION中的每个SELECT语句必须具有相同的列数
- 这些列也必须具有相似的数据类型
- 每个SELECT语句中的列也必须以相同的顺序排列
- 每个SELECT语句必须有相同数目的列表达式
- 但是每个SELECT语句的长度不必相同
SELECT <字段1>, <字段2>, ... FROM <表1>
UNION
SELECT <字段1>, <字段2>, ... FROM <表2>
-- 默认UNION组合后无重复行
SELECT <字段1>, <字段2>, ... FROM <表1>
UNION ALL
SELECT <字段1>, <字段2>, ... FROM <表2>
--UNION ALL组合后不去除重复行
检索结果分组 GROUP BY
GROUP BY 数据分组语法可以按某个字段名对数据进行分组,常与合计函数(SUM,MAX,MIN,AVG,...)结合使用
SELECT 合计函数(<字段或表达式>)
FROM <表名>
[WHERE <条件>]
GROUP BY <字段名>;
合计函数无法与 WHERE 关键字一起使用,于是SQL中增加了 HAVING 子句,一般用来筛选 GROUP BY 后的数据:
SELECT 合计函数(<字段或表达式>)
FROM <表名>
[WHERE <条件>]
[GROUP BY <字段名>]
HAVING <带有合计函数的条件表达式>;
举例:
SELECT Customer,SUM(OrderPrice) FROM Orders
WHERE Customer='Bush' OR Customer='Adams'
GROUP BY Customer
HAVING SUM(OrderPrice)>1500
-- 筛选客户 "Bush" 或 "Adams" 拥有超过 1500 的订单总金额。
SQL 中的别名
通过使用 SQL,可以为表名称或列名称指定别名(Alias)。
SELECT <字段名> AS <别名>
FROM <表名>;
-- 字段的别名
SELECT <字段名>
FROM <表名> AS <别名>;
-- 表的别名
AS 关键字是可以省略的,别名不能和表中已有的字段名重名。
SQL 数据操作
插入记录 INSERT
INSERT INTO <表名> VALUES (值1, 值2, ...);
-- 向表中插入新记录,值的顺序应与表字段顺序一致
INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...);
-- 向表中插入新记录,值的顺序应与指定字段顺序一致
-- 如果字段是自增或自减、有默认值的,可以不在指定的字段中出现
INSERT INTO <表名> (字段1, 字段2, ...) VALUES
(值1, 值2, ...),
(值1, 值2, ...),
...;
-- 一次性插入多个记录
INSERT INTO <表1> [(字段1, 字段2, ...)]
SELECT 字段1, 字段2, ...
FROM <表2>
[WHERE <条件>];
-- 使用另一个表填充一个表 []表示可选
-- 上一条语句也可以这样写:
SELECT (字段1, 字段2, ...)
INTO <表1> [IN <数据库文件>]
FROM <表2>
[WHERE <条件>];
修改记录 UPDATE
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE <条件>;
-- 更新指定条件的记录的值
-- 注意如果不指定WHERE,则所有的记录都会更新
UPDATE更新的值可以使用表达式,例如 SET score=score+10 就是给当前行的 score 字段的值加上了10。
删除记录 DELETE
DELETE FROM <表名> WHERE <条件>;
-- 删除指定条件的记录
-- 注意如果不指定WHERE则表中的全部记录都将被删除!
SQL 函数
不同的数据库管理系统有不同的函数功能,这里仅仅列了一点常用函数,更详细的介绍需要参考官方文档或自行搜索。
MySQL手册函数部分:https://dev.mysql.com/doc/refman/8.0/en/functions.html
SQL 中的合计函数
又叫聚合(Aggregate)函数,合计函数计算一组值并返回单个值,通常与 SELECT 语句的 GROUP BY 联用。用法见 GROUP BY 条目。
| 函数 | 描述 |
|---|---|
AVG([ALL | DISTINCT] expression) |
求平均值 |
COUNT([ALL|DISTINCT] expression) |
计数 |
COUNT(*) |
返回表中的记录数 |
MAX(expression) |
取最大值 |
MIN(expression) |
取最小值 |
SUM([ALL|DISTINCT] expression) |
求和 |
STD( expression) |
求总体标准差 |
使用 ALL 关键字将会对数据进行操作,使用 DISTINCT 关键字将会对数据去重后进行操作。默认使用 ALL 。
SQL 中的其他常用函数
| 函数 | 描述 |
|---|---|
UCASE(str) |
大写转换 |
LCASE(str) |
小写转换 |
UPPER(str) |
大写转换 |
LOWER(str) |
小写转换 |
MID(<字段>,<起始位置,从1开始>[,长度]) |
提取子串 |
REPLACE(<字段>,<模式串>,<目标串>) |
替换子串 |
LEN(str) |
获取文本中值的长度 |
TRIM(str) |
移除始末空白 |
CONCAT(str1,str2,...) |
连接字符串 |
SQRT(expression) |
开平方 |
ROUND(<字段>,<小数位>) |
四舍五入到指定小数位 |
RAND(seed) |
产生0~1之间的随机数 |
NOW() |
返回当前系统的日期和时间 |
SQL运算符
运算符用于表达式中,常见运算符有以下几种:
- 算术运算符
- 比较运算符
- 逻辑运算符
算术运算符
a=10,b=20
| 运算符 | 描述 | 例子 |
|---|---|---|
| + | 加法,执行加法运算。 | a + b = 30 |
| - | 减法,执行减法运算。 | a - b = -10 |
| * | 乘法,执行乘法运算。 | a * b = 200 |
| / | 用左操作数除以右操作数。 | b / a = 2 |
| % | 用左操作数除以右操作数并返回余数。 | b % a = 0 |
比较运算符
a=10,b=20
| 符号 | 描述 | 例子 |
|---|---|---|
| = | 等于 | (a = b) = false. |
| <> | 不等于 | (a <> b) = true. |
| > | 大于 | (a > b) = false. |
| < | 小于 | (a < b) = true. |
| >= | 大于等于 | (a >= b) = false |
| <= | 小于等于 | (a <= b) = true. |
逻辑运算符
| 符号 | 描述 |
|---|---|
| IN | 为列指定多个可能的值 |
| ALL | 将值与另一个值集中的所有值进行比较 |
| ANY | 根据条件将值与列表中的任何适用值进行比较 |
| SOME | ANY的别称 |
| AND | 逻辑与运算 |
| OR | 逻辑或运算 |
| NOT | 逻辑非运算 |
| EXISTS | 检查子查询是否至少会返回一行数据 |
| BETWEEN | 在某个范围内 |
| LIKE | 匹配某种模式 |
| IS NULL | 字段值是否为NULL |
| IS NOT NULL | 字段值是否不为NULL |
IN、ALL、ANY用法
-- 这里只是条件表达式,一般跟在WHERE后
<比较对象> <比较运算符> ANY (<子查询>)
<比较对象> IN (<子查询>);
<比较对象> <比较运算符> SOME (<子查询>)
<比较对象> <比较运算符> ALL (<子查询>)
<子查询> 是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字)。
<子查询> 可以是值的序列 (值1, 值2, ...) ,也可以是子查询 (SELECT column FROM table)。
举例:
age < ANY (SELECT age FROM student)
age IN (SELECT age FROM student)
age IN (16,17,18,19,20)
age > ALL (SELECT age FROM student)
EXISTS、BETWEEN、LIKE用法
-- 这里只是条件表达式,一般跟在WHERE后
EXISTS (<子查询>)
BETWEEN <值1> AND <值2>
LIKE <模式>
使用 LIKE 时的模式有两个通配符(MySQL中):
% :表示零个,一个或多个字符
_ :表示单个字符
举例:
EXISTS (SELECT * FROM student WHERE class_id=class.id)
BETWEEN 1 AND 100
LIKE 'a__d%'
IS NULL、IS NOT NULL用法
-- 这里只是条件表达式,一般跟在WHERE后
<字段> IS NULL
<字段> IS NOT NULL
SQL表达式
SQL的表达式有以下几种:
- 布尔表达式
- 数值表达式
- 日期表达式
布尔表达式
布尔表达式主要跟随在WHERE之后用作条件表达式。
数值表达式
数值表达式用来执行数学计算,可以替代<值>的位置。
SQL内置部分函数如 AVG() SUM() COUNT() 用于对表或特定表列执行所谓的聚合数据计算。
日期表达式
日期表达式返回当前系统日期和时间值:
SELECT CURRENT_TIMESTAMP;
SELECT GETDATE();
































































NewYear , 然而我上学期刚学
, 然而我上学期刚学